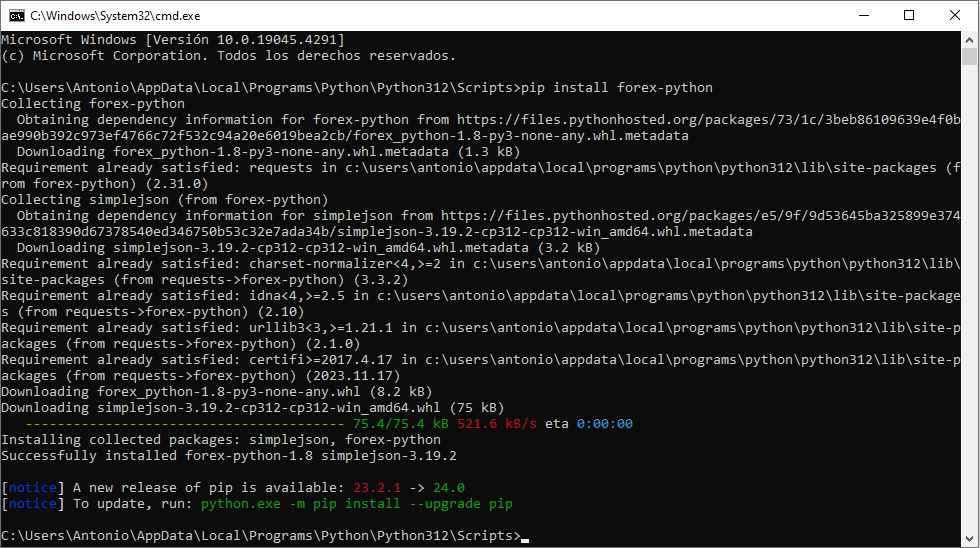
Hace algunas semanas estuvimos viendo el modo en que podíamos crear una calculadora de divisas mediante la obtención del cambio actual de moneda a través de ‘yfinance‘. En el día de hoy os mostramos otro sistema para realizar conversiones de moneda de un modo más sencillo y directo, en el que solamente haremos uso de la librería ‘forex-python‘. Una herramienta útil para trabajar con tasas de cambio y conversiones entre diferentes monedas en Python, y que instalaremos en nuestro sistema mediante ‘pip‘:
Una vez instalada la librería podemos empezar a experimentar con ella. Para ello comenzaremos importando la clase ‘CurrencyRates‘ para a continuación crear una instancia de la misma:

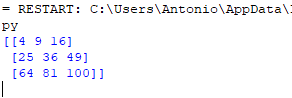
A continuación podemos empezar a hacer uso de los métodos de la clase. Por ejemplo podemos empezar obteniendo la tasa de cambio de una moneda (por ejemplo el Dolar estadounidense ‘USD’) con respecto a otras principales. Para ello emplearemos la función ‘get_rates()‘ que tomará por argumento la moneda en cuestión:
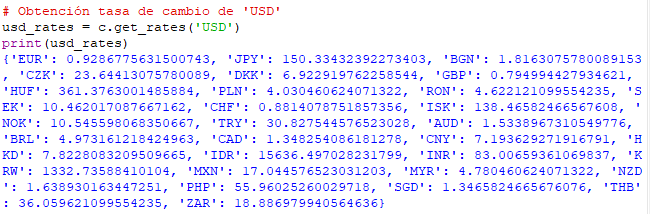
Obtenemos de este modo un diccionario en el que se muestra la tasa de cambio del Dolar frente a otras monedas internacionales como el Euro (‘EUR’), Yen japonés (‘JPY’), Libra inglesa (‘GBP’)…etc.
Por su parte, también podemos acceder a la tasa de cambio de la moneda de referencia frente a otra de modo individual, con ‘get_rate()‘. En este caso introduciremos como argumentos la moneda de referencia y aquella frente a la que queremos obtener dicha tasa de cambio:

A su vez, podemos utilizar la función ‘convert()‘ para cambios entre monedas manejando cantidades de un modo bien sencillo. De ese modo, supongamos que queremos saber a cuantos Dolares canadienses (‘CAD‘) equivalen 100 Dolares estadouinidenses (‘USD’). En esta ocasión introduciremos como tercer argumento, dicha cifra. Como se ve en el ejemplo, aplicaremos a la salida un redondeo de 2 decimales (como hicimos también en el ejemplo anterior):

No obstante, cuando presentamos resultados de conversión entre monedas, puede resultar de interés mostrar el símbolo de la moneda en cuestión. Para ello deberemos importar la clase ‘CurrencyCodes‘ creando la pertinente instancia a continuación. Tras lo cual, utilizaremos el método ‘get_symbol()‘ pasando como argumento la moneda cuyo símbolo queremos obtener (en nuestro caso, el de la Libra inglesa ‘GBP’)
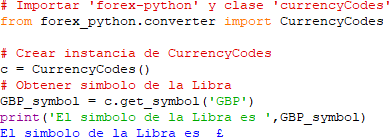
La obtención de los correspondientes símbolos de moneda nos permitirá mejorar el modo en que se presenta el resultado de la conversión:
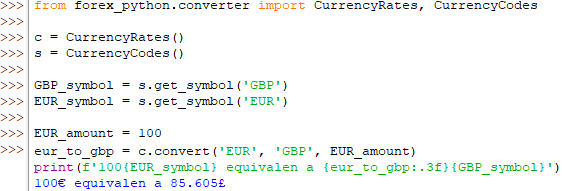
Finalmente hacer alusión a la posibilidad de realizar conversiones de diferentes monedas y a monedas digitales como es el Bitcoin:

CONCLUSION:
La biblioteca ‘forex-python‘ es una herramienta poderosa y fácil de usar para trabajar con conversiones de divisas y tasas de cambio en Python. Con su capacidad para realizar conversiones precisas y obtener tasas de cambio actualizadas, es una opción invaluable para desarrolladores que trabajan en aplicaciones financieras, comerciales y de comercio electrónico. Esperamos que este artículo haya proporcionado una introducción útil al mundo de las conversiones de divisas. ¡Ahora es tu turno de explorar y experimentar con esta potente biblioteca!
Saludos.