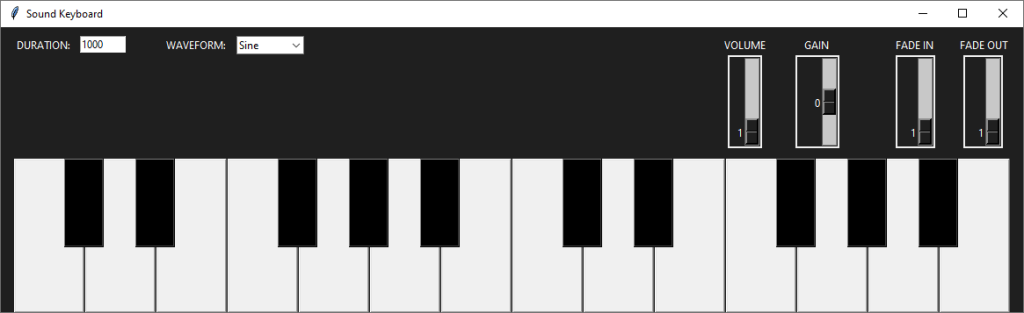
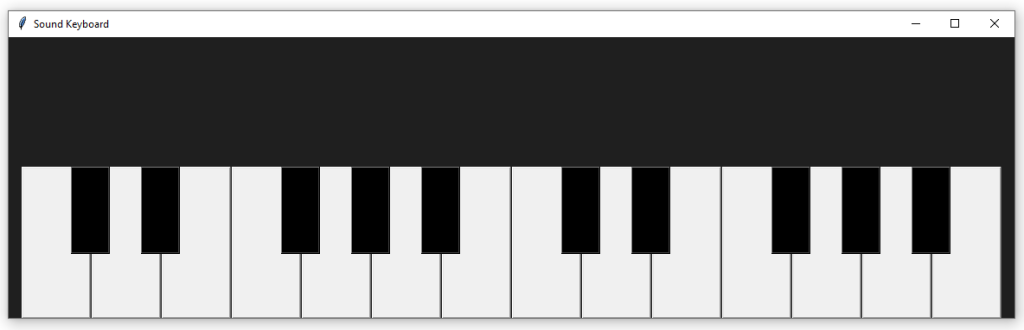
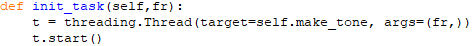Hace un par de semanas, estuvimos viendo el modo de generar tonos de audio haciendo uso de la librería «pydub» (la cual instalamos mediante el comando «pip install pydub«). Lo que hoy nos proponemos hacer es poner en practica los conocimientos adquiridos entonces para crear un sencillo teclado musical (usando «tkinter«) de dos octavas como el que mostramos a continuación:
Como siempre, lo primero que haremos es importar los recursos que vamos a necesitar, recordando que debemos instalar previamente tanto la librería «pydub» como el software «ffmpeg«:
Importados los recursos que vamos a emplear, pasaremos a crear nuestro teclado, empezando por definir sus dimensiones, título y color:
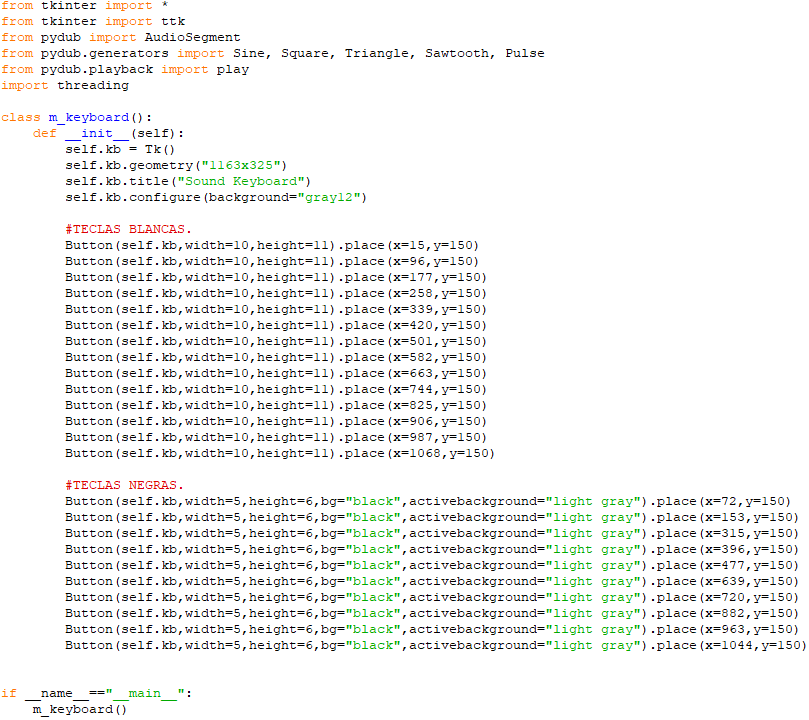
A continuación, procedemos a introducir los distintos elementos de nuestro teclado, empezando por las teclas blancas (usando la función «Button»):
Pasando a continuación a hacer los mismo con las teclas negras:
A partir de ahora, nuestra labor será la de hacer que nuestro teclado emita un sonido para cada tecla, pudiendo a su vez variar una serie de características tales como la duración de cada nota, el tipo de onda, la amplitud de esta, el volumen y el desvanecido tanto inicial como final. Para poder estableces tales parámetros, necesitaremos incluir una serie de elementos en nuestra interfaz:
En este bloque, nos hemos encargado de introducir los elementos gráficos. Concretamente un «Entry» para establecer la duración en milisegundos de cada nota (para lo cual también hemos creado la variable «self.duration«) que establecemos en 1000 como valor predeterminado), un «comboBox» en el que mostraremos las posibles formas de onda que podrá adoptar nuestro sonido (las cuales se almacenan en la variable «self.WaveForms«) y cuatro «sliders» con los que podremos regular el volumen, la amplitud (ganancia) y el desvanecido inicial y final (para estos parámetros crearemos también las respectivas variables). Si ejecutamos ahora obtenemos el siguiente resultado:
A su vez, nos hemos asegurado que en le campo «DURATION:» únicamente puedan introducirse valores enteros, para lo que hemos creado la variable «validatecommand» y la función «self.valid_duration()«:
Ya tenemos los elementos mediante los cuales podemos configurar la sonoridad de nuestro teclado, ahora hace falta hacerlo sonar. Para ello crearemos una función a la que hemos llamado «self.make_tone()» que generará nuestra nota en función del tipo de onda, duración y frecuencia (la cual será única para cada tecla y que definiremos más adelante):
A su vez, para evitar que al tocar una nota la ventana se nos pueda quedar congelada, usaremos una nueva función «self.init_task()» que ejecutará (con un «Thread«) la función anterior como un subproceso en paralelo:
Esta es la función que conectaremos directamente con cada uno de los «Button» correspondientes a cada tecla y que tomará como argumento, ahora sí, el valor correspondiente a la frecuencia de cada nota. Valor que especificaremos a través de la correspondiente función «lambda()» tanto para las teclas blancas como para las negras:
Y con ello tendríamos creado nuestro sencillo teclado musical cuyo código completo podéis consultar en el siguiente enlace:
Saludos y bienvenidos un día mas a vuestro blog sobre programación en Python. En el día de hoy vamos a ver el modo en que podemos leer y escribir archivos «.csv» haciendo uso del módulo «csv» de Python. Para nuestro ejemplo usaremos un archivo de nombre «names.csv» el cual contiene una serie de nombres organizados en 3 campos «first_name«, «last_name» y «email«:
Cada línea muestra el nombre, apellido y correo electrónico.
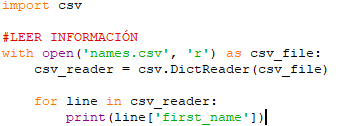
Así lo primero que haremos será abrir nuestro archivo e imprimir la información contenida en el. Para ello, naturalmente empezaremos importando el módulo «csv»:
Como se ve, hemos usado el método «open()» indicando el nombre del archivo que queremos abrir y el modo en que lo queremos abrir (modo lectura ‘r‘) para a continuación crear la variable «csv_reader» que contendrá la información de nuestro archivo la cual, a su vez, hemos obtenido con el método «.reader()«. Finalmente para mostrar el contenido emplearemos un ciclo en el recorreremos cada línea del documento para imprimirlo en pantalla:
Se nos muestra el contenido de nuestro archivo organizado en listas, lo cual a su vez nos permite seleccionar el contenido a mostrar introduciendo el índice correspondiente a columna que queremos mostrar. Así supongamos que queremos que se muestre únicamente la columna referente a los emails:
Como se ve, el código introducido es el mismo que el anterior con la salvedad del índice introducido («[2]«) para cada línea. De este modo. al ejecutar solo se mostrarán de cada línea el elemento correspondiente a dicha posición en la lista:
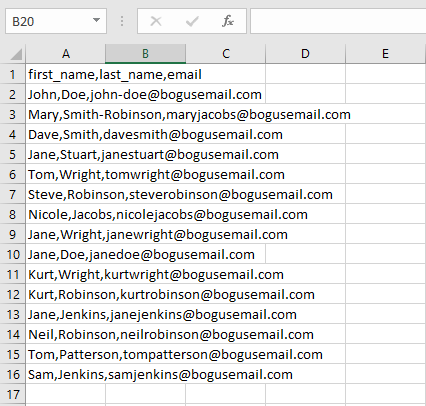
Obtenemos así los correos e nuestros nombres incluyéndose en la primera línea el nombre del campo seleccionado «email«. No obstante podemos hacer que se muestre la lista de correos sin el nombre de dicho campo usando la función «next()«:
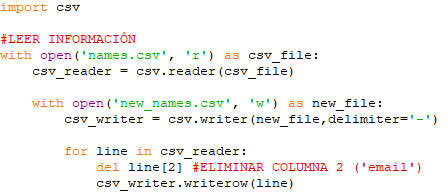
Volviendo ahora a nuestro archivo «csv«, vemos como la información de mostraba separada por comas, un modo de mostrarla que quizás no nos resulte muy estético en determinadas circunstancias. Por ello, vamos a proceder a crear un nuevo archivo al que llamaremos «new_names.csv» en el que emplearemos el guion (‘-‘) como criterio separador:
Hasta ahora hemos mostrado la información por líneas en listas de elementos. No obstante, también podemos mostrar esta en pares clave/valor donde la primera es el nombre de la columna y la segunda es el valor correspondiente en la respectiva fila. Para esto usaremos el método «DictReader()» tal y como se muestra a continuación:
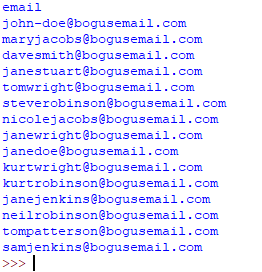
Lo que al ejecutar, nos mostrará las líneas de nuestro archivo, ordenadas en pares clave/valor:
Este modo de organizar la información a mostrar nos facilita también el elegir la columna que deseamos analizar. Así por ejemplo si queremos ver solo la lista de los nombres de pila (columna «first_name«):
Nótese que en este caso no hemos tenido que hacer uso de la función «next()» para mostrar únicamente los valores sin incluir el titulo de su respectiva columna.
Pero no solo podemos elegir que parte de la información contenida, se nos muestra. También podemos crear nuestro nuevo archivo de modo que no cuente con alguna parte de la información. Así en nuestro ejemplo podemos crear el archivo «new_names.csv» de modo que no contenga la información referida al email de cada nombre:
Lo cual nos generará un nuevo archivo «new_names.csv» únicamente con la información referente a los nombres de pila y a los apellidos.
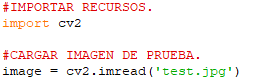
Bienvenidos una semana más a «El programador Chapuzas», vuestra página sobre programación en lenguaje «Python» en una ocasión en la que nos proponemos llevar a cabo la medición de la similitud existente de dos archivos de imagen «data1.jpg» y «data2.jpg» respecto a una imagen de referencia «test.jpg«, usando la librería «opencv» (la cual instalaremos con «pip install cv2«).
«test.jpg»
«data1.jpg»
«data2.jpg»
Una vez que tenemos las imágenes con las que vamos a trabajar, crearemos un nuevo archivo «.py» al que llamaremos «image_compare.py» y en el que empezaremos importando la librería que vamos a emplear («opencv«). Tras lo cual, empezaremos abriendo el archivo de la imagen de referencia («test.jpg«) con el método «imread()«:
Tras ello procederemos a convertir nuestra imagen a escala de grises usando «cvt.Color()» pasando como argumentos la variable en el que se contiene la información de la imagen («image«) y la operación de transformación que queremos realizar («BGR2GRAY«):
Obtenida la imagen en escala de grises, procederemos a obtener los datos de su histograma, empleando la función «calcHist()«:
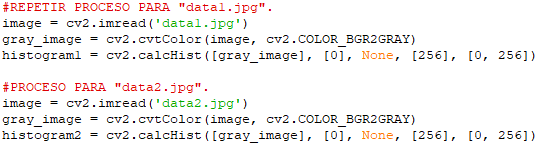
Pues bien esta última información obtenida (que almacenamos en la variable «histogram«) es la que vamos a utilizar para medir el grado de similitud o diferencia de esta imagen de prueba respecto de las otras dos. De las que a su vez, tendremos que obtener igualmente sus respectivos histogramas (que almacenaremos en las variables «histogram1» e «histogram2«), repitiendo el mismo proceso:
Finalmente, una vez que hemos obtenidos los histogramas tanto de la imagen de referencia («test.jpg«) como de sendas imágenes a comparar («data1.jpg» y «data2.jpg«), pasaremos a medir el grado de similitud comparando sus respectivos histogramas. Así empezaremos midiendo la similitud entre la imagen de referencia y «data1.jpg» determinando su distancia euclídea:
Iniciamos aquí un ciclo en que vamos comparando los valores de cada pixel de «test.jpg» con su correspondiente en «data1.jpg» (nótese que usamos el ciclo para asegurarnos de que cada pixel de «test» tenga su correspondiente en «data1«). Terminado el proceso, obtendremos un valor de diferencia acumulada entre ambas imágenes. De modo que cuanto más elevado sea este valor mayor diferencia habrá entre ambas imágenes. Este proceso volveremos a repetirlo para el caso de «data2.jpg«, para finalmente usar un «if/else» con el que mostrar el resultado de la comparativa entre ambas imágenes respecto de la referencia:
Así, si ejecutamos nuestro programa obtendremos el siguiente (y previsible) resultado:
Tenéis el código completo del ejercicio, así como las imágenes de muestra utilizadas en la carpeta «compare_image.zip» la cual podéis obtener en el siguiente repositorio:
En artículos anteriores hemos visto ya las posibilidades que ofrece la librería «pydub» a la hora de manipular y editar archivos de audio. Posibilidades las cuales no se limitan al manipulado de archivos de audio preexistentes, sino que se extiende a la posibilidad de generar (a través del módulo «pydub.generators«) dichos audios de un modo sencillo. No obstante, antes de nada, debemos empezar instalándonos (si no lo hemos hacho ya) la librería «pydub» («pip install pydub«) la cual hace uso del software «ffmpeg» cuyo proceso de instalación podéis ver en el siguiente vídeo:
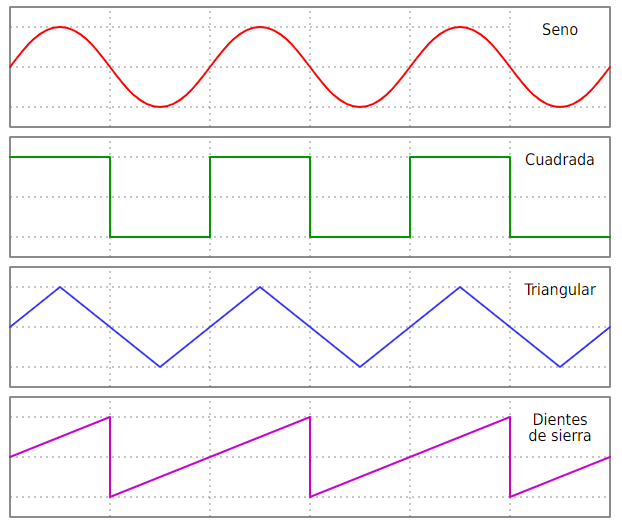
Una vez que tengamos todo listo, podemos empezar a generar nuestros archivos de audio, que en este caso van a consistir en tonos de 3 segundos de duración, a una frecuencia de 440Hz para cada una de las formas de onda que se muestran a continuación:
Una vez fijado el objetivo de nuestra práctica, empezaremos importando los recursos que vamos a necesitar:
Como se ve, la totalidad de los recursos que importamos pertenecen a la librería «pydub«. Así, importamos «AudioSegement» para trabajar con archivos de audio, usamos «pydub.generators» para generar audio con distintas formas de onda (Sine, Square, Triangle y Sawtooth) y «pydub.playback» para reproducir el tono generado. Importado todo lo necesario, pasaremos a generar nuestros tonos:
Tal y como e puede aprecia, para los 4 tonos usamos la sintaxis en la que solo varía el método para generar los diferentes tipos de onda («Sine«, «Square«, «Triangle» y «Sawtooth«) y en los que introducimos como argumentos la frecuencia (440Hz) y la duración en milisegundos («duration=3000«).
Con esto tendríamos generados nuestros tonos e audio, desde aquí, para reproducir cualquiera de ellos simplemente emplearíamos la función «play()«:
A su vez, podemos usar la función «append()» para generar un audio que en el que se encadenen los tonos creados anteriormente:
Generados todos nuestros tonos, podemos proceder a almacenarlos en nuestro equipo mediante el método «export()» al que pasaremos el nombre que queramos para el archivo y su formato (que será «.wav» para todos los audios excepto para el «mutitone» que almacenaremos en formato «mp3«:
Partiendo de estos conocimientos, podemos ir más allá y crear una sencilla (y minimalista) interfaz gráfica que nos permita generar audios en distintas formas de ondas, introduciendo la duración en milisegundos y la frecuencia. El código de dicha aplicación podría ser el que se encuentra en el siguiente enlace y en cuyo repositorio tenéis la carpeta «wave_tones.zip» con los audios generados en este ejercicio:
Bienvenidos una vez más a vuestro blog sobre programación en lenguaje Python, en un día en el que vamos a emplear la conocida librería «scikit-learn» para desarrollar un sencillo ejemplo de regresión lineal simple (dejaremos la múltiple para una futura ocasión) en dicho lenguaje. Para quién no lo sepa la «regresión lineal» constituye el algoritmo más sencillo de aprendizaje supervisado dentro del paradigma del «machine learning» donde lo que se trata es de obtener la relación entre unas variables independientes («X«) y una variable dependiente («Y«). De modo que teniendo una serie de variables predictoras, se obtenga la relación con una variable cuantitativa a predecir. La regresión lineal explica la variable «Y» con las variables «X«, y obtiene la función lineal que mejor se ajusta o explica esta relación. Tal y como ya hemos indicado, en esta ocasión nos centraremos en la modalidad de «regresión lineal simple» en la que trabajaremos con una sola variable predictora.
Así, el modelo de regresión lineal considera que partiendo de un conjunto de observaciones la media de de la variable dependiente «Y» se relaciona de forma lineal con las variables independientes «X» acorde con la siguiente ecuación:
Donde «Y» es la variable dependiente, «X, X1…» son las variables independientes, «ϵ» es la medida de error del modelo y «β0» y «β1» son respectivamente, el interceptor y la pendiente del mismo. Estos dos últimos parámetros son los que obtendremos mediante el entrenamiento del modelo (de modo que sus correspondientes estimaciones se ajusten lo más posible a los datos proporcionados) . De manera que nos permitirán calcular el valor de cada variable dependiente «Y» a partir de su correspondiente variable «X» con el mínimo margen de error posible.
IMPLEMENTACIÓN EN PYTHON.
A continuación vamos a ver como podemos aplicar este algoritmos en Python haciendo uso de la librería «scikit-learn» (la cual deberemos instalar con el comando «pip install scikit-klearn«) mediante un sencillo ejemplo en el que nos proponemos ver la relación existente entre el número medio de habitaciones de un conjunto de viviendas en Boston y su valor medio. Para ello importaremos el conjunto de datos (dataset) «load_boston» que nos viene incluido en la librería. En el siguiente enlace tenéis los datasets (e información sobre los mismos) de prueba que ofrece «scikit-learn» y que importaremos a través del módulo «datasets«:
Para ello empezaremos importando los recursos que vamos a necesitar: «numpy» para trabajar con arrays, «matplotlib» para graficar nuestro modelo y «sklearn» del que a su vez importaremos «datasets» (en donde se encuentra el dataset que vamos a emplear como ejemplo) «linear_model» (que contiene el algoritmos de regresión lineal que queremos usar) y «train_set_split» (que usaremos para dividir los datos entre datos de entrenamiento, y datos de prueba del modelo):
Una vez que tenemos importado todo lo necesario para nuestro propósito, pasaremos a cargar nuestros datos de entrada del módulo «dataset» introduciendo «datasets.load_boston()«:
Si imprimimos la información del mismo, obtendremos una gran cantidad de información, la cual, en un principio puede resultar incomprensible:
Afortunadamente contamos en «sklearn» con una batería de métodos que nos permitirán acotar y aislar la información concreta que necesitamos para nuestro proyecto. Por ejemplo, podemos emplear el método «.keys()» para obtener los tipos de información que contiene nuestro dataset:
De los cuales podemos usar «feature_names» para obtener los nombres de las columnas en la que se encuentran estructurados los datos:
Y «DESCR» para obtener una descripción del significado de cada una de ellas:
Viendo el resultado obtenido, observamos que la información de entrada que nos interesa en este caso (el número medio de habitaciones por vivienda) es el correspondiente a la columna «RM«, la cual, ocupa la posición 5 dentro de la lista de columnas obtenidas anteriormente (recordando siempre que contamos las posiciones desde 0). Esta información es importante en la medida que la usaremos para determinar los datos que conformarán el eje X de nuestra gráfica inicial:
Definidos los datos de entrada para el eje «X» haremos lo propio para los del eje «y» para a continuación usar la librería «matplotlib» para mostrar la gráfica de dispersión inicial, usando los métodos «xlabel()» e «ylabel()» para definir las correspondientes etiquetas para cada eje:
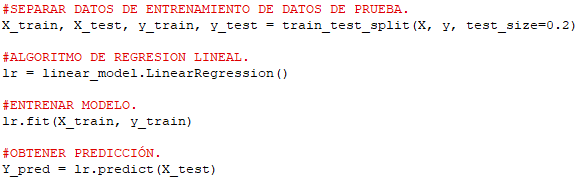
Partiendo de estos datos, vamos a pasar a entrenar nuestro modelo, obteniendo los valores. Para ello vamos a utilizar parte de los datos de entrada (concretamente el 80%) para entrenar el modelo y el resto (20%), para probarlo. Es por esto por lo que en su momento importamos «train_test_split«:
Como se aprecia, usamos «train_test_split» para obtener por una parte los datos de entrenamiento («X_train» e «y_train«) y los datos destinados a probar el modelo («X_test» e «y_test«). Tras ello definimos nuestro algoritmos de regresión («linear_model.LinearRegression()«) para a continuación (usando el método «.fit()» proceder al entrenamiento del modelo usando los datos de entrenamiento como argumento. Finalmente procedemos a probar nuestro modelo mediante el método «.predict()» usando los datos de prueba la variable «X_test«.
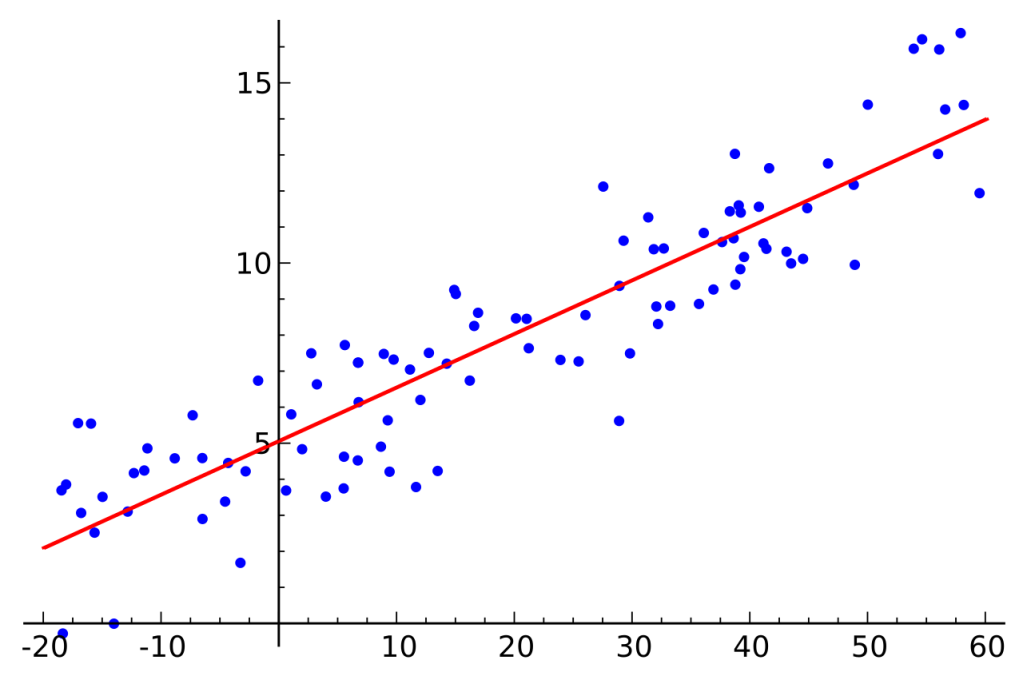
Una vez obtenido el modelo. Solo nos queda hacer uso nuevamente de «matplotlib» para representar la función de regresión que representaremos mediante una línea:
Tenemos un resultado que ya a primera vista nos hace ver que nuestro modelo no es especialmente preciso ya que se ve como quedan muchos puntos fuera de nuestra línea. Esto es debido a la naturaleza elevadamente dispersa de los datos de entrada.
Una vez obtenida la representación gráfica, podemos obtener los valores numéricos de la pendiente y el interceptor del que hablábamos al principio. Para ello escribiremos «lr.coef_» y «lr._intercept» respectivamente:
Finalmente, podemos mostrar el valor (sobre 1) del nivel de precisión de nuestro modelo mediante el método «.score()» introduciendo como argumentos los datos de entrenamiento:
Obteniendo un valor algo inferior a la mitad, lo cual confirma que nuestro modelo no es todo lo preciso que cabría desear, lo cual, haría necesario la búsqueda de otro algoritmo que se adecuara mejor a los datos de los que disponibles. Aunque eso será materia de artículo futuro.
En el siguiente enlace tenéis el código completo del ejercicio: