Hace unas pocas semanas, estuvimos viendo el modo en que podíamos crear, consultar y organizar un dataframe de manera sencilla, utilizando la librería «pandas«. No obstante, que duda cabe de que en ciertas ocasiones, podemos necesitar almacenar la información de una tabla, dentro de un archivo al que podamos acceder más tarde. Es por ello que en el día de hoy vamos a ver como podemos crear un archivo en excel, utilizando dicha librería, la cual, en Windows, podemos instalar usando el comando «pip«:
Una vez instalado, iniciaremos la creación de nuestro archivo «.xlsx» importando primero «pandas» y el módulo «ExcelWriter«, tras lo cual, definiremos la información que queremos guardar usando el método «DataFrame()» tal y como vimos en su momento:
Hasta ahora, solo hemos definido la información que vamos a almacenar en nuestro archivo excel. Para esto último (la creación del archivo excel) empezaremos definiendo el objeto que vamos a emplear para la escritura (al que llamaremos ‘writer‘) definiendo a su vez el nombre de nuestro futuro archivo, para a continuación, pasar nuestra información a dicho formato, usando la función ‘to_excel()‘. Finalmente, usaremos ‘save()‘ para guardar el documento:
Hecho esto, deberá aparecer en la carpeta en la que estemos ubicados, un nuevo archivo de extensión ‘.xlsx‘ con la información introducida:
Y con esto quedaría vista la manera en la que podemos utilizar ‘pandas‘ para crear archivos en Excel. En futuras entregas, veremos también como podemos acceder, dentro de nuestro código, a la información de dichos archivos de un modo directo.
Hace algunas semanas estuvimos dando nuestros primeros pasos en materia de programación con sockets. En aquella ocasión, hablamos acerca de que son, su funcionamiento básico y realizamos nuestra primera conexión cliente-servidor. En esta segunda ocasión, vamos a ver el modo en que podemos transferir un archivo desde un cliente a un servidor, no sin antes dejar aquí el esquema que explica el modo en que se realiza la conexión entre los dos nodos y que explicamos en su momento:
Lo que nos proponemos a hacer en esta practica es utilizar un cliente (al que llamaremos «sender.py«) para transferir (más bien copiar) la información de un archivo de imagen («image.png«) alojado en el directorio en el que se va a ejecutar dicho cliente, a un servidor (llamado «receiver.py«) que se encargará de recibir dicha información del cliente, y con ella, generar una copia de la imagen en el directorio en que este se ejecute.
«image.png»
Para ello, lo primero será crear nuestro cliente «sender.py» cuyo código (el cual explicaremos) es el que sigue:
«sender.py»
Como se ve, empezamos importando la librería para trabajar con sockets de Python, y el módulo «os» (que emplearemos para obtener el tamaño del archivo a enviar). Acto seguido pasaremos a establecer la dirección IP del servidor de destino (como vamos a realizar la transferencia de información entre nodos ubicados en un mismo equipo, bastará con poner «localhost«) y el puerto a través del cual haremos la comunicación (9999 en este caso). Tras ello, crearemos nuestro cliente especificando el tipo de conexión que queremos realizar para a continuación usar la función «connect()» para realizar la solicitud de conexión con el servidor introduciendo la dirección IP y el puerto ya especificados. Una vez hecho esto, pasaremos a abrir el archivo que queremos enviar al servidor (pudiendo obtener el tamaño del mismo con «os.path.getsize()«) y a utilizar la función «send()» para mandar datos como el nombre que tendrá en el punto de destino y el tamaño de dicho archivo. A su vez, usaremos «sendall()» para mandar la información del archivo (que leeremos con «.read()«). También mandaremos el string en formato bytes «<END>» para indicarle al servidor que la transferencia de información ha sido completada. Finalmente escribiremos «file.close()» y «client.close()» para cerrar el archivo y el cliente respectivamente.
Hasta aquí lo referente al cliente («sender.py«) encargado de enviar la información. Ahora nos toca crear el servidor «receiver.py» que se encargará de recibir la información de nuestro archivo y guardarla en el directorio en que lo ejecutemos:
«receiver.py»
Como en el caso anterior, empezamos definiendo las variables «HOST» y «PORT» relativas a la dirección IP (en este caso del cliente) y el puerto de escucha respectivamente, para a continuación crear el servidor, el cual pondremos a la escucha de posibles solicitudes de conexión con la función «listen()«. Una vez establecida conexión con nuestro cliente (con la función «.accept()«, emplearemos las funciones «recv()» y «decode()» para obtener la información acerca del nombre del futuro archivo y su tamaño, enviada desde «sender.py» para después crear el nuevo archivo en la carpeta de destino (aquella en la que estemos ejecutando «receiver.py«) con «open()«. El proceso de escritura del archivo lo llevaremos a cabo a través de un «while» en el que en cada iteración, recibiremos un paquete de 1024 bytes de información que iremos agregando a la variable (previamente creada) «file_bytes«. Esta operación se llevará a cabo mientras que el valor de la variable «done» sea «False» («while not done:«) cuyo valor solo se hará «True» si los últimos 5 bytes recibidos («file_bytes[-5:]«) se correspondan con el string «<END>» que como recordarán es el string que establecimos en «sender.py» como criterio para indicar al servidor cuando a finalizado el envío de información y por tanto, cuando deja de ser necesario la espera nueva información. Usando la información compilada en «file_bytes» procederemos a la escritura del archivo («file.write(file_bytes)«) en el directorio de destino. Completado el proceso, pasaremos a cerrar el archivo creado así como el cliente y el servidor, mediante la función «close()«.
Una vez que hemos creado nuestro creado nuestro cliente «sender.py» y nuestro servidor «receiver.py» pasaremos a ejecutar este último en el directorio en el que queremos crear la copia de nuestra imagen:
Servidor «receiver.py» a la espera de conexiones entrantes.
Nuestro servidor quedará así a la espera de conexiones entrantes. A continuación ejecutaremos el cliente «sender.py» en la carpeta en la que tengamos alojada la imagen que queremos transferir:
El cliente «sender.py» hace una solicitud de conexión a «receiver.py» para transferir el archivo de imagen.
Nuestro cliente hará la solicitud de conexión al servidor, para una vez aceptada esta, transferir la información al servidor, el cual, imprimirá el nombre que le hemos mandado para la imagen copiada y el tamaño del archivo:
El servidor muestra en pantalla el nombre del nuevo archivo y su tamaño, recibidos desde el cliente.
Finalmente, para comprobar que todo ha salido bien, comprobaremos el contenido de la carpeta de destino en el que deberá encontrarse la copia de la imagen original:
Si repasamos detenidamente el código de «receiver.py» veremos, una serie de líneas de código comentadas. Estas son las relativas a la posible inclusión de una barra de progreso para nuestro servidor. Pasemos a des-comentarlas:
«receiver.py» que incluye barra de progreso.
La inclusión de una barra de progreso en el terminal del servidor, puede ser útil en aquellas ocasiones en las que vayamos a transferir grandes cantidades de información, de modo que nos interese visualizar el proceso de transferencia. En el ejemplo visto, su uso no estaba justificado, dado que la transferencia a sido inmediata. De todos modos, podemos usar la función «time.sleep()» para como se vería en caso que fuera necesario:
El uso de barras de progreso, puede ser útil para visualizar el proceso de transferencia de grandes cantidades de datos.
Y hasta aquí este artículo en el que hemos visto como utilizar una conexión cliente-servidor para realizar la transferencia de un archivo, tomando su información de la carpeta de origen, para reconstruirlo en otro directorio.
En los siguientes enlaces tenéis el código completo tanto del servidor como del cliente, creados en este artículo:
Saludos y bienvenidos a vuestro sitio sobre programación en Python. Como muchos ya sabréis, ‘moviepy‘ es una librería que nos permite la generación y edición de archivos de video, la cual podremos instalar en nuestro equipo utilizando el comando ‘pipinstallmoviepy‘:
En el tutorial de hoy, vamos a ver como podemos generar, de forma sencilla, un vídeo en el que, mediante la división de pantalla, muestre más de un vídeo a la vez. Para ello, empezaremos importando la propia librería ‘moviepy‘ junto a los módulos ‘VideoFileClip‘ y ‘clips_array‘:
Una vez importados los recursos con los que vamos a trabajar, podemos iniciar la creación de nuestro vídeo combinado usando el método «VideoFileClip()» al que pasaremos, para cada vídeo, el nombre del archivo en cuestión, especificando a su vez (usando el método «subclip«) el intervalo de tiempo en segundos que queremos seleccionar (en nuestro ejemplo, tomaremos los 4 primeros segundos de cada uno):
Una vez cargados los vídeos con los que vamos a trabajar (4 en este caso) utilizaremos «clips_array()» para especificar los videos que vamos a mostrar en el resultado, introduciendo estos en formato array tal y como se muestra a continuación:
Finalmente, una vez definido el contenido de nuestro futuro vídeo (que hemos almacenado en la variable «comb1»), pasaremos a crear nuestro vídeo, que mediante el método «write_videofile()» (al que pasaremos el nombre del nuevo vídeo) iniciando un proceso cuya duración dependerá naturalmente del tamaño y duración de los videos seleccionados:
OUTPUT:
Como se ve, en este primer ensayo hemos tomado únicamente los dos primeros videos de los 4 que hemos cargado. No obstante, podemos utilizar «clips_array()» tanto para añadir más videos (lo que supondrá también que el tiempo de generación aumente) como para definir la estructura en la que estos se presentarán:
OUTPUT:
Al mismo tiempo ‘moviepy‘ nos permite establecer márgenes entre los videos compartidos, a la hora de cargar estos, usando el método ‘margin()‘ pasándole el grosor que queremos para dicho margen:
OUTPUT:
Se muestra la presencia de un margen para dividir los vídeos en el resultado final. A su vez, una vez que hayamos terminado, deberemos proceder a cerrar los videos abiertos:
Para la elaboración de este tutorial se ha usado una serie de videos libres de derechos, los cuales, pueden descargarse en la siguiente página web:
Saludos y bienvenidos una semana más a vuestro blog sobre programación en Python, en una ocasión en la que vamos a ver como podemos extraer el texto de un archivo «.pdf» usando la librería «PyPDF2» que podéis instalar con el comando «pip install pypdf2«.
Una vez que tengamos instalada nuestra librería, podremos empezar a usarla para extraer el texto de nuestro documento PDF. Para ello, comenzaremos importando esta y abriendo el documento en cuestión:
Abierto el documento, pasaremos a crear el lector que se encargará de acceder a la información del mismo. Esto lo haremos mediante la función «PdfFileReader()» a la que pasaremos el documento abierto en el paso anterior:
Definido el lector, ahora podemos acceder a cualquier pagina del documento, utilizando la función «getPage()» del propio lector, y especificando el numero de la página cuyo texto extraeremos, haciendo uso de la función «extractText()» para imprimirlo por pantalla:
OUTPUT:
Obtenemos así el texto de la página solicitada impreso en la pantalla. Finalmente, una vez que hayamos terminado deberemos cerrar nuestro documento utilizando la función «close()«:
En el artículo de esta semana vamos a ver el modo de crear en ‘Python‘, un dataframe, agregarle información y realizar consultas básicas, haciendo uso de la librería ‘Pandas‘, la cual, en el caso de no tenerla ya disponible en nuestro equipo, procederemos a instalarla con el comando ‘pip install pandas‘:
Una vez que lo tengamos instalado, podemos empezar, creando un dataframe vacío, lo cual, haremos de manera sencilla, utilizando el método «DataFrame()» pasando a la variable «columns» una lista con las columnas que queremos para nuestro dataframe:
Una vez creado nuestro dataframe, podemos empezar a añadirle elementos mediante la función «append()» mediante un diccionario en el que las claves habrán de ser los nombres de las correspondientes columnas y los valores serán su información asociada:
A su vez, cuando tengamos un dataframe con varias filas, podemos realizar consultas y búsquedas tanto por etiquetas como por números, usando para ello las funciones «loc()» e «iloc()«:
Vemos como en la primera consulta (en la que hemos usado la función «loc«, hemos accedido al nombre especificando el índice de la fila (teniendo en cuenta que el índice del primer elementos es 0) y el nombre de la columna. Por su parte, en la segunda consulta hemos empleado «iloc» cambiando el nombre de la columna por su correspondiente índice.
También podemos acceder a la totalidad de los valores de cada columna (con sus índices) especificando entre corchetes el nombre de la misma:
Algo parecido podemos hacer frente a los valores de cada fila, utilizando en este caso, el método «iloc» y especificando el correspondiente índice de fila:
Como hemos señalado arriba, podemos usar la función «DataFrame()» para crear un dataframe vacío al que después podamos ir añadiendo elementos mediante la función «append()«. No obstante, es posible que prefiramos crear nuestra tabla, con los datos ya incorporados. Para esto podemos utilizar una serie de listas que luego podamos agregar a la función, junto a los nombres de las columnas:
Se crea, de este modo nuestro dataframe, sobre el cual, podemos empezar a realizar nuestras consultas, las cuales, pueden consistir también en el cumplimiento de ciertas condiciones. Por ejemplo, digamos que sobre la tabla actual, queremos obtener las filas de los alumnos cuya nota es mayor o igual a 5:
A su vez, también podemos obtener un booleano para cada fila que nos indique si se cumple o no la condición:
Finalmente veremos como podemos organizar el orden de nuestros datos. Empezaremos por ordenar alfabéticamente los nombre de los alumnos:
Para ello, simplemente hemos utilizado la función «sort_values()» introduciendo como argumentos el nombre de la columna por la que queremos ordenar el dataframe y si queremos que el orden sea ascendente o no (nótese también que aunque las filas aparezcan en otro orden, la asignación del índice para cada una, aparece inalterado). Finalmente decir que podemos realizar dicha ordenación introduciendo más de una columna:
Y con esto quedaría visto este repaso a las principales operaciones de creación y consulta de dataframes mediante el uso de la librería «pandas» que nos podrá ser de gran ayuda a la hora de almacenar y gestionar nuestro datos.
Saludos una vez más y bienvenidos sean a vuestro blog sobre programación en lenguaje Python, en una ocasión en la que, tal y como reza el título sobre estas líneas, vamos a ver como se puede representar gráficamente una señal de audio, de un modo sencillo, utilizando las librerías «wave«, «matplotlib» y «numpy«. De estas librerías, la primera viene instalada con Python (con lo que nos bastará simplemente con importarla) mientras que «matplotlib» en caso de que no la tengamos instalada, deberemos instalarla en nuestro equipo, previamente:
Otra librería que vamos a utilizar es «numpy» la cual, al igual que en el caso anterior, deberemos instalarla previamente si no lo hemos hecho ya:
Una vez que tengamos todo instalado, podremos empezar a graficar nuestras señales de audio. Así, lo primero que haremos será crear un nuevo archivo al que llamaremos «signal_plot.py» en el que empezaremos haciendo las importaciones necesarias:
El siguiente paso será, cargar el archivo de audio cuya señal queremos graficar. Para ello utilizaremos la función «.open()» especificando que queremos abrirlo en modo lectura binaria «rb«:
Una vez que tenemos cargado nuestro archivo (y almacenado en el objeto «audio«) pasaremos a obtener una serie de datos necesarios para generar nuestra grafica: En primer lugar necesitaremos conocer la frecuencia de muestreo («frame rate» o «sample frequency») que no es otra cosa que el número de muestras por segundo empleadas en la señal (cuyo valor habitualmente será de 44100), obteniendo este dato mediante la función «getframerate()» y almacenándolo en la variable «sample_freq«. En segundo lugar, usaremos la función «audio.getnframes()» para obtener el número total de muestras (o «frames»). Finalmente obtendremos la señal con la información de nuestro audio, utilizando la función «readframes()» introduciendo -1 como argumento para indicar que queremos leer el total de la información. Una vez obtenidos estos datos, procederemos a cerrar nuestro archivo de audio («audio.close()«):
Para representar nuestra señal usando «matplotlib» necesitaremos antes convertir esta (almacenada en «signal_wave«) en un array de valores que podamos usar en nuestra gráfica. A su vez definiremos la variable «times» con la que podremos representar (en el eje «x») el tiempo de la señal. Para esto último necesitaremos conocer también la duración en segundos del audio, la cual, será igual al número de muestras dividido por su frecuencia («n_samples/sample_freq«):
Una vez que tenemos todos los datos, simplemente nos resta usar las funciones y métodos que ya conocemos de «matplotlib» para proceder a la representación gráfica de nuestra señal:
OUTPUT:
Consiguiendo así una representación gráfica de nuestra señal de audio con solo unas pocas líneas de código, las cuales podéis ver, al completo a continuación:
En computación, nos encontramos a menudo con datos almacenamos o recuperados de una aplicación que se encuentran desordenados, sin ningún orden lógico, y se nos hace necesario organizarlos y/o clasificarlos para procesarlos correctamente o usarlos más eficientemente. Es en este punto, donde los algoritmos de ordenación, pueden tener un papel importante. En este artículo (y en futuros artículos) vamos a ir viendo los principales algoritmos de ordenación y su implementación en Python. empezando en esta ocasión por el más sencillo de todos: El ordenamiento de burbuja (o ‘bubble sort‘).
EN QUE CONSISTE:
Como hemos señalado, el ordenamiento de burbuja es el más sencillo de todos y consiste en recorrer, un número de veces, los distintos elementos de la lista, realizando la comparación de pares de elementos consecutivos de modo que (para una ordenación de menor a mayor) si el elemento de la izquierda es mayor que el de la derecha, se realiza un intercambio de sus respectivas posiciones. Este recorrido de comparaciones se realizará sucesivas veces hasta que ya no haya pares que intercambiar:
Comparación de pares de valores en el Ordenamiento de Burbuja.
Animación del Ordenamiento de Burbuja.
También hay que reseñar el hecho de que si bien, este es al algoritmos más sencillo, también es el más ineficiente en lo que respecta a consumo de tiempo, ya que este aumenta notablemente a medida que crece el número de elementos a ordenar. Con lo que este procedimiento solo es recomendado para listados que cuenten con pocos elementos.
IMPLEMENTACIÓN EN PYTHON.
Pasemos a ver como podemos implementar nuestro algoritmo en Python. Para ello definiremos una función (a la que llamaremos «bubbleSort()«) que tomará como único argumento la lista de elementos a ordenar:
Como puede verse, lo primero que hacemos es definir la variable «n» que será igual a la longitud de la lista de elementos a ordenar («n = len(lista)«). Tras ello, empleamos dos ciclos «for» mediante los que vamos a recorrer la lista de elementos, tantas veces como elementos haya en la misma. Así en cada recorrido de la lista, se irá realizando la comparación de pares contiguos, de modo que cuando el elemento de la izquierda sea mayor que el de la derecha («if lista[j] > lista[j + 1]:«) se procederá al intercambio de posiciones entre los mismos para lo que previamente habrá que almacenar el valor de la izquierda, en una variable temporal («temp«) para que el lugar del valor de la izquierda sea ocupado por el de la derecha («lista[j] = lista[j + 1]«) antes que el de la derecha sea ocupado por el de la izquierda («lista[j+1] = temp»). Este procedimiento se repetirá tantas veces como elementos haya en la lista, para finalmente retornar la lista ordenada («return lista«).
Una vez definida nuestra función de ordenación, pasaremos a aplicarla sobre una lista de elementos numéricos desordenados:
OUTPUT:
Lista desordenada y lista ordenada por la función «bubbleSort()»
Como ya hemos señalado con anterioridad, este algoritmo se va haciendo cada vez más costoso a medida que la lista de elementos vaya aumentando. Aún así, podemos realizar algunos cambios en nuestra función para mejorar su rendimiento. Estos cambios van a afectar, fundamentalmente al número de recorridos completos de la lista, necesarios para completar la tarea.
Para entender mejor esto, vamos a añadir a nuestra función original dos variables («cambios» y «recorridos«) con las que contabilizaremos el número de cambios de posición realizado en cada pasada y el número total de recorridos de lista realizados, respectivamente:
OUTPUT:
Se muestra en el output tanto el número de cambios de posición realizado en cada recorrido completo de la lista (13 en el primero, 12 en el segundo…) como el número total de recorridos realizados (que será el del número de elementos -1). No obstante, se observa como a partir del recorrido 12, el número de cambios de posición realizados es 0, lo que indica que el proceso de ordenación ya está completado, siendo innecesarios realizar nuevos recorridos de lista. Por ello, para optimizar nuestra función, podemos agregar esta condición (que el número de cambios sea 0) para mediante un «break» finalizar la ejecución del proceso:
OUTPUT:
Conseguimos, de este modo evitar los 5 últimos recorridos de lista, con el consecuente ahorro de tiempo. De todos modos se trata este del método de ordenación más ineficiente computacionalmente hablando (válido solo para cantidades bajas de elementos a ordenar) siendo por ello que en futuros artículos abordaremos procedimientos más complejos, pero también, más eficientes y menos costosos.
En el artículo de la pasada semana, estuvimos viendo la forma en la que podíamos mostrar los diferentes canales de color, de una imagen, usando la librería «opencv«. Hoy completaremos aquella explicación, mostrando como podemos hacer uso de histogramas para analizar mejor la distribución de las intensidades de color (tanto en escala de grises, como en cada uno de los canales BGR). Para ello, partiremos del código que usamos para mostrar la imagen de muestra:
OUTPUT:
Lo primero que vamos a hacer es mostrar el histograma relativo a los valores de intensidad de color de nuestra imagen. Para ello, lo primero que haremos será convertir nuestra imagen a escala de grises, para facilitar el cálculo de su histograma. Esto (como vimos en el articulo anterior) lo hacemos con «opencv» y la función «cvtColor()«:
OUTPUT:
CALCULANDO HISTROGRAMAS.
Una vez obtenida nuestra imagen a escala de grises, podemos pasar al cálculo de su histograma, para su posterior representación gráfica. Para ello emplearemos la función «calcHist()«. A su vez, generaremos nuestra representación utilizando la librería «matplotlib«, motivo por el que deberemos importarla previamente:
Como se ve, hemos usado la función «calcHist()» para calcular nuestro histograma, pasando como argumento, en primer lugar, la lista de imágenes (en este caso, solo una) cuya distribución de valores queremos conocer. En segundo lugar, deberemos pasar el número de canales de color que queremos analizar (en este caso, tratándose de una imagen en escala de grises, el valor será 0). En tercer lugar, si queremos utilizar alguna máscara para analizar una determinada porción de la imagen, deberemos especificarla (en este caso lo dejaremos en «None«). Tras ello, especificaremos el número de contenedores (dado que los posibles valores de intensidad varían entre 0 y 255, el valor será de 256). Finalmente, ese mismo rango lo especificaremos como último argumento. Hecho el cálculo, usamos «matplotlib» para mostrar la gráfica siguiente:
Obtenemos así, una gráfica en la que se muestra el número de pixeles (eje «y«) que presentan cada uno de los posibles valores de intensidad (eje «x«). Esto que acabamos de hacer para la imagen en escala de grises, podemos hacerlo igualmente para cada uno de los canales de color en los que esta se puede descomponer, (proceso este que vimos en el anterior artículo y que consistía en la aplicación de la función «split()«):
Como se ve, hemos empezado realizando la descomposición de nuestra imagen en sus tres canales BGR (variables «b«, «g» y «r«) para a continuación, realizar el cálculo de sus correspondientes histogramas (almacenándose en las variables «blue_hist«, «green_hist» y «red_hist«) que a continuación pasaremos como argumentos (junto al título) de una función para mostrar las gráficas, (a la que llamamos «hist()«), obteniendo los siguientes resultados:
OUTPUT:
Blue_Histogram.png
Green_Histogram.png
Red_Histogram.png
Examinando el resultado, podemos ver como es en el canal rojo donde se da las mayores cantidades de pixeles con valores de intensidad más elevados. Lo cual, en este caso, puede intuirse fácilmente examinando las tonalidades predominantes en la imagen original.
Cuando trabajamos con imágenes digitales a color, podemos entender estas como un arreglo en el que el valor de color de cada pixel, viene dado por la combinación de tres valores de intensidad (que variarán de 0 a 255) que se corresponden con los tres canales de color: rojo, verde y azul (que a su vez son los colores básicos de cuyas combinaciones se pueden obtener toda la gama de colores del espectro visible). Pues bien, en este artículo, veremos como podemos obtener por separado dichos canales de color usando la librería «opencv» y que instalaremos con el comando «pip install opencv-python«.
Para nuestro análisis usaremos una imagen a color, la cual leeremos y mostraremos en pantalla, utilizando las funciones ‘imread()‘ y ‘imshow()‘ respectivamente:
OUTPUT:
Una vez cargada nuestra imagen de muestra podemos empezar usando «numpy» y su función «array» para obtener el arreglo de valores de intensidad para cada uno de los canales de color:
OUTPUT:
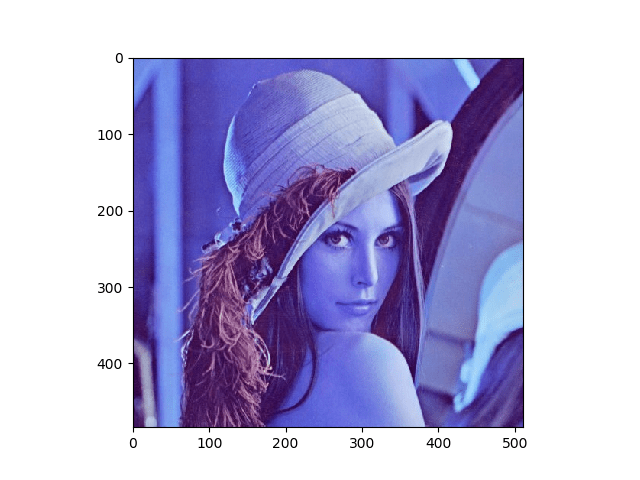
Obtenemos así representados las intensidades de color, de cada pixel, para los canales azul, verde y rojo (en ese orden). En este caso concreto vemos como los valores de intensidad del canal rojo son, en general, más altos, lo cual concuerda con las tonalidades imperantes en la imagen de muestra.
El orden en el que aquí se muestran los valores de intensidad de cada canal viene del hecho de que «opencv» realiza la lectura de imágenes utilizando el espacio de color «BGR» (en lugar del más común «RGB«). Esto puede plantear problemas, por ejemplo, cuando queremos mostrar una imagen leída por «opencv» utilizando otras librerías, como por ejemplo «matplotlib«:
OUTPUT:
Para estos casos, lo que podremos hacer es convertir previamente nuestra imagen de «BGR» a «RGB» empleando la función «cvtColor()«:
OUTPUT:
A su vez, este cambio también se plasmaría en el orden de los valores de intensidad en el arreglo que obtuvimos con «numpy«:
Siguiendo con nuestros canales de color, «opencv» ofrece una función («split()«) la cual nos permitirá realizar la separación de los tres canales de color, para después mostrarlos en pantalla y por separado:
OUTPUT:
Se muestra así, la distribución por separado, de las intensidades de color (entre 0 y 255) para los canales azul (imagen de la izquierda), verde (imagen central) y rojo (imagen de la derecha) en donde las regiones más claras se corresponden con los valores de intensidad más altos, sucediendo lo contrario con las regiones más oscuras, que representan los valores más bajos.
A su vez, de la misma manera que hay una función que separa los tres canales de color y nos permite representarlos por separado, también hay otra función («merge()«), a la que pasaremos una lista con las variables en las que hemos almacenado los valores de intensidad para cada canal, y que nos permitirá reconstruir la imagen original a partir de los tres canales:
OUTPUT:
Una consideración final que podemos hacer, es con referencia a la salida que obtuvimos cuando mostramos, por separado los tres canales de color. En aquella ocasión de nos mostraron tres imágenes en escala de grises. Lo cual es debido a que estas eran unidimensionales (entendido esto como que sus arreglos estaban compuestos por un único valor de intensidad por pixel).
Para mostrar las intensidades de cada canal, por separado y con su color correspondiente, lo que haremos será incorporar dos valores más por pixel en sus respectivos arreglos. Para ello lo que haremos será usar la función «merge()» para combinar por separado cada canal de color con los valores de una imagen en negro y con las mismas dimensiones, la cual generaremos con la función «zeros()» de «numpy» (dicha imagen en negro tendrá que tener las mismas dimensiones que las imágenes a combinar):
OUTPUT:
En este artículo hemos visto el modo en que podemos mostrar la distribución por separado, de los valores de intensidad para cada canal de color, en una imagen digital, así como el modo en que podemos reconstruir la imagen original a partir de dichos canales. También hemos hecho notar el hecho de que «opencv» lee las imágenes en formato «BGR» y la necesidad de su conversión a formato «RGB» para trabajar con otras librerías como «matplotlib«.
Saludos programadores, en el artículo de hoy, vamos a ver un sencillo ejemplo de como hacer uso de la función «Radiobutton()» en tkinter con la que podremos introducir en nuestras interfaces una serie de opciones que podrán ser marcadas por el usuario de nuestro programa. Se trata este de un elemento, también, muy utilizado para la confección de formularios:
Veamos ahora como crear nuestro widget paso a paso. Lo primero que haremos será importar ‘tkinter‘ y generar nuestra ventana principal, estableciendo su tamaño:
OUTPUT:
Generada nuestra ventana, es hora de empezar a introducir los elementos a seleccionar, además de un botón de «RESET» y una etiqueta, en principio sin texto, en la que mostraremos la opción seleccionada. Para hacer uso de estos elementos emplearemos las funciones «Radiobutton()«, «Button» y «Label» definiendo para el caso de las opciones a seleccionar y del botón, las funciones a las que vamos a llamar. También cabe destacar el argumento «value» de «Radiobutton()» con el que indicaremos la variable a la que nos estamos refiriendo (en este caso «option«):
Una vez definidos los elementos de la interfaz, definiremos también las funciones «select()» y «reset()» a la que referenciamos con el argumento «command» y que se encargarán de mostrar en la etiqueta de salida («outLabel«) la opción seleccionada, en el primer caso y de resetear la opción escogida, en el segundo:
OUTPUT:
También podemos utilizar las variables «activebackground» y «activeforeground» para establecer el color de fondo y texto, que adoptarán los «radiobuttons» al hacer click sobre ellos:
OUTPUT:
Y hasta aquí este sencillo ejercicio en el que hemos visto, de forma sencilla, como podemos incluir este widget para selección de opciones, en nuestras interfaces de usuario utilizando tkinter.
En el siguiente enlace podéis ver el código completo de este ejercicio: