‘R’ es un lenguaje de programación, de código abierto, orientado al análisis estadístico, muy popular en la comunidad académica y de investigación, así como en la industria para el análisis de datos y la modelización estadística y que cuenta con una gran cantidad de paquetes y bibliotecas para una variedad de tareas analíticas. Pues bien, hoy vamos a ver un sencillo ejemplo de como utilizar este potente lenguaje dentro de nuestro código Python, haciendo uso de la librería ‘rpy2‘, creada para ser un puente de comunicación entre ambos lenguajes.

Pero antes de continuar, deberemos asegurarnos de tener instalados todos lo recursos necesarios. Dado que, tal y como ya hemos señalado, ‘rpy2‘ es una librería que conecta nuestro código Python con los recursos y utilidades del lenguaje ‘R‘, tendremos que tener también instalado este último (al final del artículo dejaremos la dirección de la página desde la que realizar la descarga). Por lo que a la librería ‘rpy2‘ se refiere, haremos la instalación por el procedimiento habitual para las librerías de Python:

EJEMPLO DE COMO USAR ‘R’ EN PYTHON:
Veamos ahora un sencillo ejemplo en el que nos proponemos realizar un análisis de regresión lineal simple sobre el conjunto de datos ‘mtcars‘ en ‘R‘ ajustando un modelo lineal que predice la eficiencia del combustible (‘mpg‘) en función del peso del automóvil (‘wt‘) visualizando el correspondiente gráfico de dispersión y línea de regresión mediante la librería ‘ggplot2‘ de ‘R‘.
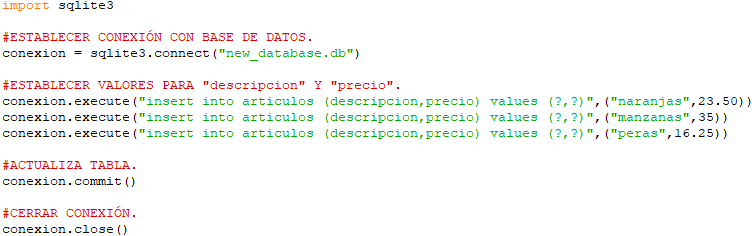
Así, empezaremos creando un nuevo archivo Python en el que, naturalmente, empezaremos importando las librerías y recursos de los que vamos a hacer uso:

Tras ello, procederemos a activar la conversión automática entre ‘pandas‘ y ‘R‘ e instalar los paquetes de ‘R‘ que vamos a usar en el ejemplo. Entre el que se encuentra el paquete ‘base‘ que es el que nos proporciona la tabla de ejemplo ‘mtcars‘ de la extraeremos nuestra información:

Tras ello procederemos a cargar los datos de muestra correspondientes a cada uno de los modelos de vehículos cuya información se recoge en ‘mtcars‘. Para luego, aplicar el modelo de regresión lineal utilizando ‘mpg‘ y ‘wt‘ como variables dependiente e independiente, respectivamente. Esta operación la definiremos usando la sintaxis de ‘R‘ (‘ linear_model <- lm(mpg ~ wt, data = mtcars)‘). Aplicado el modelo, obtendremos los datos resumidos del mismo mediante la función ‘summary()‘ (también en ‘R‘):

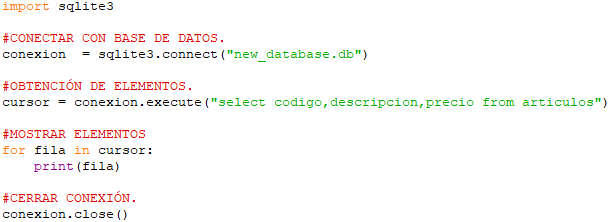
Como se puede apreciar, una vez hecha la regresión, volveremos a convertir los datos obtenidos en un dataframe de pandas de modo que podamos imprimirlos en nuestro editor de Python mediante la función ‘print()‘:

Finalmente, pasaremos a mostrar la relación (inversa en este caso) entre ambas variables mediante un gráfico de dispersión al que incorporaremos la línea de regresión. Dicho grafico lo generaremos, usando nuevamente, la sintaxis de ‘R‘ y su librería para graficas ‘ggplot2‘:

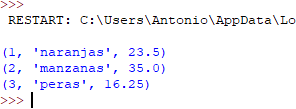
OUTPUT:

CONCLUSIÓN:
Para terminar, el uso de ‘R‘ en combinación con Python a través de la interfaz ‘rpy2‘ ofrece una herramienta de gran utilidad para el análisis de datos y su visualización. En este artículo, hemos demostrado cómo cargar datos, realizar un análisis de regresión lineal y generar gráficos de dispersión con líneas de regresión utilizando el conjunto de datos ‘mtcars‘. Por su parte, la capacidad de integrar funciones estadísticas y de visualización de ‘R‘ con la flexibilidad y facilidad de uso de Python abre un amplio abanico de posibilidades para investigadores y analistas de datos, permitiéndoles aprovechar lo mejor de ambos mundos para abordar sus problemas de análisis de datos de manera eficiente y efectiva.
Enlace a la pagina oficial de ‘R’:
Saludos.