

Hace algún tiempo estuvimos hablando de la programación concurrente en Python. En aquel articulo vimos como la concurrencia es una técnica fundamental en programación que permite ejecutar varias tareas de forma simultánea o solapada, mejorando el rendimiento y la capacidad de respuesta de las aplicaciones. Pues bien, en el artículo de hoy, hablaremos un poco de concurrent.futures, el cual, constituye un módulo de la biblioteca estándar de Python (por lo que no se requiere de ninguna instalación adicional) que nos permitirá ejecutar tareas de manera concurrente de un modo sencillo. Además nos permitirá trabajar tanto con hilos (threads) como con procesos facilitando la paralelización de tareas y sin tener que gestionar manualmente los detalles de bajo nivel de la concurrencia.
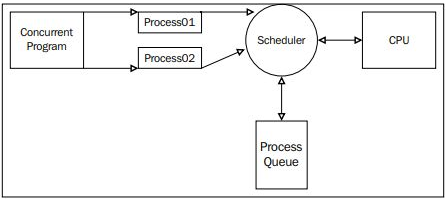
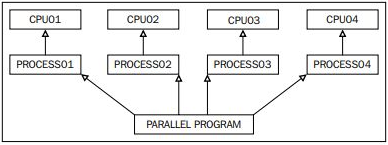
Este módulo se basa en el concepto de ejecutores (executors), que son objetos responsables de administrar un grupo de hilos o procesos y ejecutar funciones de manera asíncrona. Los dos ejecutores principales son ThreadPoolExecutor, orientado a tareas de entrada/salida, y ProcessPoolExecutor, más adecuado par tareas que requieren un uso intensivo de la CPU.
DESCARGA CONCURRENTE DE PÁGINAS WEB CON ThreadPoolExecutor.
En primer lugar, ThreadPoolExecutor es especialmente útil cuando se trabaja con operaciones que pasan mucho tiempo esperando, como solicitudes de red o acceso a archivos. Un caso típico puede ser, por ejemplo, la descarga de varias páginas web utilizando hilos, permitiendo reducir el tiempo total de ejecución:

En este código, submit() envía cada tarea al ejecutor y devuelve un objeto Future. Por su parte, el método as_completed() permite procesar los resultados a medida que cada descarga finaliza, sin esperar a que terminen todas. Esto mejora significativamente el tiempo total de ejecución frente a una versión secuencial.
OUTPUT:

USO INTENSIVO DE CPU CON ProcessPoolExecutor.
Port otra parte, cuando las tareas requieren mucho cálculo, como operaciones matemáticas complejas, el uso de hilos puede no ser eficiente debido al Global Interpreter Lock (GIL) de Python. Para estos casos, ProcessPoolExecutor permite distribuir el trabajo entre varios procesos, aprovechando mejor los núcleos del procesador. En el siguiente ejemplo abordaremos un caso típico en el que puede ser útil este enfoque como es la adición de valores muy grandes:

En este caso, utilizamos ProcessPoolExecutor para ejecutar en paralelo una tarea intensiva de CPU, concretamente el cálculo de la suma de una secuencia de números grandes. Para ello definimos primero la función suma_grande(), que realiza el cálculo mediante un bucle acumulativo. A continuación, dentro del bloque if __name__ == «__main__», creamos una lista de valores que después enviaremos, cada uno, como tarea independiente a un conjunto de procesos mediante executor.submit(). Cada proceso ejecuta la función de forma autónoma devolviendo el resultado a través de un objeto Future. Por su parte, el bucle as_completed() permite recoger los resultados a medida que los procesos finalizan, mostrando la suma calculada para cada valor. Finalmente, como en el caso anterior, usaremos time.time() para medir el tiempo total de ejecución del conjunto de cálculos.
OUTPUT:

En esta salida queda bien ilustrada la idea de que as_completed() nos permite tomar los resultados a medida que se van completando, en el hecho de que el resultado para 20000000 se muestra el último (lo cual se entiende al ser el mas grande y requerir más tiempo), a pesar de figurar el primero en la lista valores. A diferencia del resultado que obtendríamos con un enfoque secuencial el cual, además, consumiría más tiempo:

UTILIZANDO executor.map().
El método map() resulta muy útil cuando se desea aplicar una función a una lista de elementos (como vimos en el caso anterior) y obtener los resultados en el mismo orden. Veamos, así, otro ejemplo en el que nos proponemos convertir una lista de temperaturas de grados Celsius a Fahrenheit:

De este modo, obtenemos un código más compacto que el que tendríamos usando submit() no siendo necesario manejar explícitamente objetos Future, mejorando la legibilidad cuando las tareas son simples.
OUTPUT:

MANEJANDO EXCEPCIONES EN TAREAS CONCURRENTES.
Un aspecto capital a tener en cuenta en aplicaciones que usan la concurrencia es el relativo al manejo de excepciones. Veamos un sencillo ejemplo en el que procesamos una lista de divisiones donde algunas operaciones pueden generar errores, como la división por cero:

En este código, el manejo de excepciones es fundamental para garantizar que un error en una tarea concurrente no interrumpa la ejecución del resto. Cada división se ejecuta en un hilo independiente y, si ocurre una excepción (como la división por cero), esta no se produce inmediatamente, sino que queda almacenada en el objeto Future. Al llamar a future.result(), la excepción se propaga y puede capturarse mediante un bloque try/except. De este modo, el programa puede detectar y reportar errores de forma individual, mientras permite que las demás tareas finalicen con normalidad, logrando un control robusto y seguro de fallos.
OUTPUT:

CONCLUSION.
En conclusión, el módulo concurrent.futures ofrece una forma clara y eficaz de implementar concurrencia y paralelismo en Python, permitiendo ejecutar múltiples tareas de manera simultánea sin complejidad excesiva. Su capacidad para gestionar resultados y excepciones a través de objetos Future facilita la creación de programas más robustos, ya que los errores pueden tratarse de forma individual sin afectar al resto de la ejecución. Al elegir correctamente entre ThreadPoolExecutor y ProcessPoolExecutor según el tipo de tarea a ejecutar, es posible mejorar el rendimiento y la escalabilidad de las aplicaciones, manteniendo al mismo tiempo un código legible y fácil de mantener.
Saludos.
