Saludos y bienvenidos a este segundo articulo de la serie Procesamiento de señales de audio con Python. En el artículo anterior sentamos las bases del sonido digital generando una onda seno y convirtiéndola en un archivo de audio. En esta segunda parte vamos a dar un paso clave: entender qué ocurre cuando una señal continua se muestrea, qué límites tiene ese proceso y por qué una mala elección del sample rate puede introducir errores audibles. El objetivo de este artículo es experimentar directamente con Python para escuchar, ver y provocar el aliasing, uno de los fenómenos más importantes del audio digital.
TECNICA DE MUESTREO Y EL TEOREMA DE NYQUIST.
El muestreo es el proceso fundamental que permite convertir una señal analógica, continua en el tiempo, en una señal digital formada por valores discretos que un ordenador puede almacenar y procesar. La frecuencia de muestreo (sample rate) determina cada cuánto tiempo se toma una “fotografía” de la señal original y, por tanto, define el nivel de detalle con el que esa señal será representada. Un sample rate demasiado bajo provoca pérdidas de información y distorsiones irreversibles, mientras que uno adecuado permite capturar fielmente el contenido espectral de la señal. Aquí es donde entra en juego el teorema de Nyquist (o de Nyquist – Shannon), que establece que la frecuencia de muestreo debe ser al menos el doble de la frecuencia más alta presente en la señal para evitar el aliasing, garantizando así una digitalización correcta y sin ambigüedades. Podemos plasmar dicho teorema en la siguiente expresión:

Aquí, la frecuencia se conoce como frecuencia de Nyquist. Donde cualquier componente espectral por encima de este límite no podrá representarse correctamente y dará lugar a distorsión (aliasing). Para ilustrar esta idea de un modo practico, recurriremos al siguiente programa en el que, establecido un sample rate relativamente bajo (8000 Hz), generaremos varias audios (mucho cuidado al reproducirlos, sobre todo si usan auriculares) con frecuencias cuyos valores se encontrarán tanto por debajo como por encima de Nyquist, para finalmente mostrar la grafica correspondiente a la frecuencia generada de modo incorrecto (con aliasing). Apuntar también que, dado que estamos experimentando con señales simples, la frecuencia máxima coincidirá con la asignada al principio, al ser constantes en nuestros ejemplos:

Pasemos, a continuación, a ejecutar el script:

Como se puede comprobar, la salida del programa nos muestra el valor de Nyquist que constituye la frecuencia máxima que puede ser correctamente generada y representada con un sample rate, en este caso, de 8000 Hz (ya que 8000 / 2 = 4000) de modo que de los audios generados a continuación, solo el último de ellos (con frecuencia de 45000Hz, que es superior al valor de Nyquist) se generará con aliasing. Esto no supondrá un fallo en el programa, simplemente que el tono generado no se corresponderá al que debería generarse con esa frecuencia (el sonido generado aparecerá claramente distorsionado). Esta falta de correspondencia puede verse también graficando esta última señal (cosa que hace el código a continuación):

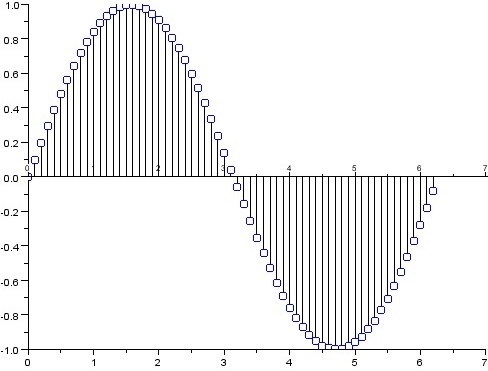
En la gráfica de una señal aliasada la forma de onda deja de parecer una senoide suave y regular, y aparece distorsionada, con oscilaciones más lentas de lo esperado. Aunque el tono original era de alta frecuencia, la señal muestreada parece corresponder a una frecuencia más baja, como si la onda se “plegara” sobre sí misma. Este efecto visual refleja exactamente el aliasing: el sistema digital interpreta erróneamente una frecuencia por encima de Nyquist como otra distinta dentro del rango permitido, produciendo una señal que no coincide ni en forma ni en contenido con la original.
ELIGIENDO FRECUENCIA DE MUESTREO ADECUADA.
A partir de este punto, cabe preguntarse por cual ha de ser el sample rate a emplear para que la totalidad de las señales se genere de manera adecuada. Esto lo haremos con la operación inversa a la empleada para calcular el valor de Nyquist:

Por lo que el sample rate, mínimo a usar en nuestro caso sería de 9000 Hz (ya que 2 * 4500 = 9000). Sin embargo, aunque el valor de 9000 Hz, aquí, cumpliría teóricamente el teorema de Nyquist para un tono de 4500 Hz, al situarse exactamente en el límite mínimo, no deja margen de seguridad y produce una representación muy pobre de la señal, con solo dos muestras por ciclo (haciendo que el audio generado sea casi imperceptible como sería en este caso). Y es que, en la práctica, las señales reales no son senoides ideales (como los que hemos estado viendo hasta ahora) y contienen armónicos, transitorios y ruido (no se preocupen, dentro de poco empezaremos a experimentar con señales compuestas), además de que los filtros antialiasing no son perfectos, por lo que trabajar al límite aumenta el riesgo de distorsión. Por esta razón, en audio se emplean frecuencias de muestreo estándar como 44.1 kHz o 48 kHz, que proporcionan suficiente margen para capturar correctamente todo el contenido espectral audible y garantizar compatibilidad, estabilidad y calidad en los sistemas de grabación y reproducción. Ejecutemos nuevamente nuestro programa, pero ahora, usando un sample rate estandard de 44100 Hz (44.1kHz):

Vemos como la situación cambia ostensiblemente al ver como el valor de Nyquist, ahora es de 22050 Hz. Lo que cubre con creces el valor de todas las frecuencias que queremos representar. Incluida la de 4500 Hz, que ahora, presentará la siguiente gráfica sin distorsiones:

CONCLUSIÓN.
En este capítulo hemos visto cómo el proceso de muestreo y la elección del sample rate condicionan de forma directa la fidelidad de una señal digital, comprobando de manera práctica qué ocurre cuando se viola el teorema de Nyquist y cómo aparece el aliasing. Hemos trabajado en el dominio del tiempo, escuchando y visualizando las señales para entender sus limitaciones. En el próximo capítulo daremos un paso más y cambiaremos de perspectiva: entraremos en el dominio de la frecuencia, trabajaremos con señales compuestas, aprenderemos a descomponer estas mediante la Transformada de Fourier (FFT) y veremos cómo analizar y visualizar su contenido espectral para comprender con mayor profundidad qué está ocurriendo realmente dentro del audio.
Saludos.